Doing this was the original Web scraping.
In those times I put several examples on my LB website, showing how to daily download weather and other data and pictures. Later I wrote a much more complex LB program to download Rosetta Code's Liberty BASIC page, and use it to dowbload ( and sometimes run) the code from about 400 separate pages. Links on my website.
However, things have moved on. Web pages are dynamically assembled when you follow a link, and it may be difficult or even impossible to get much off the page apart from screen grabbing images. There are a plethora of languages and techniques now in use for building websites and pages.
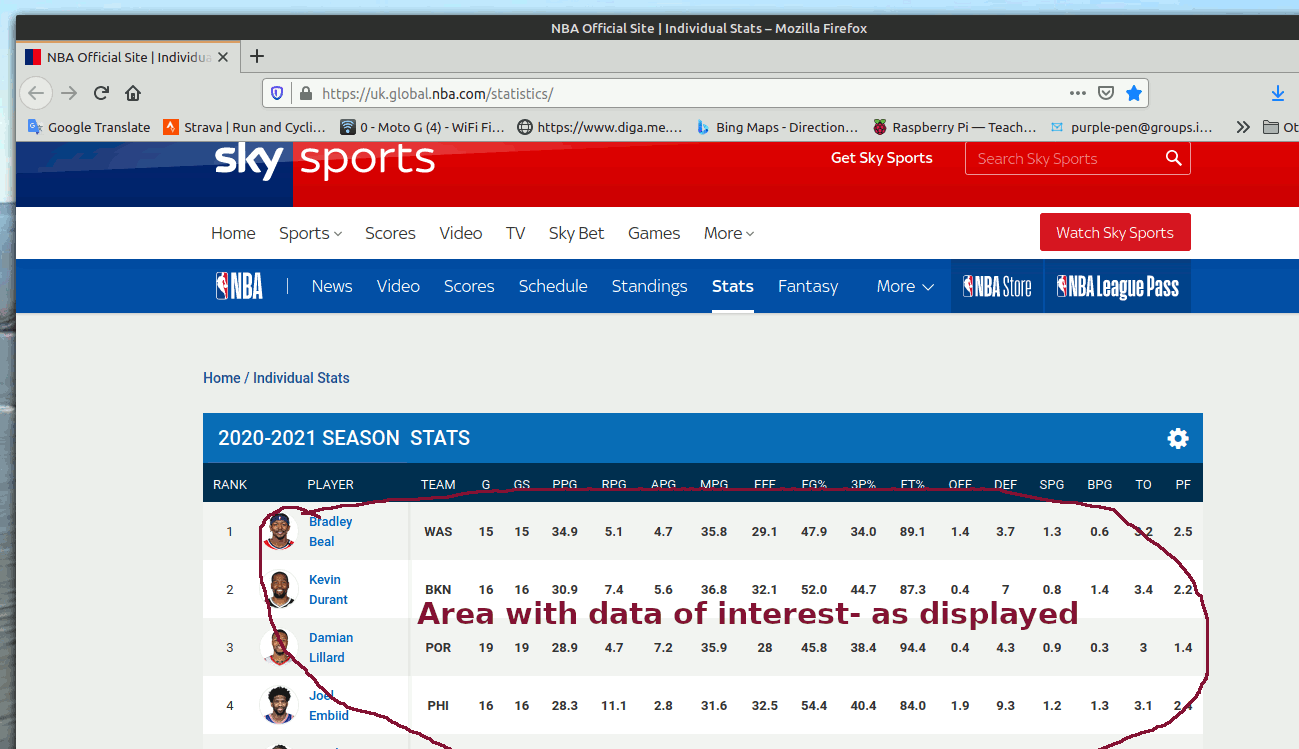
The Sky NBA page was raised as an example. You SEE a table with players' names, but if you search the source code of the page the names are not there!
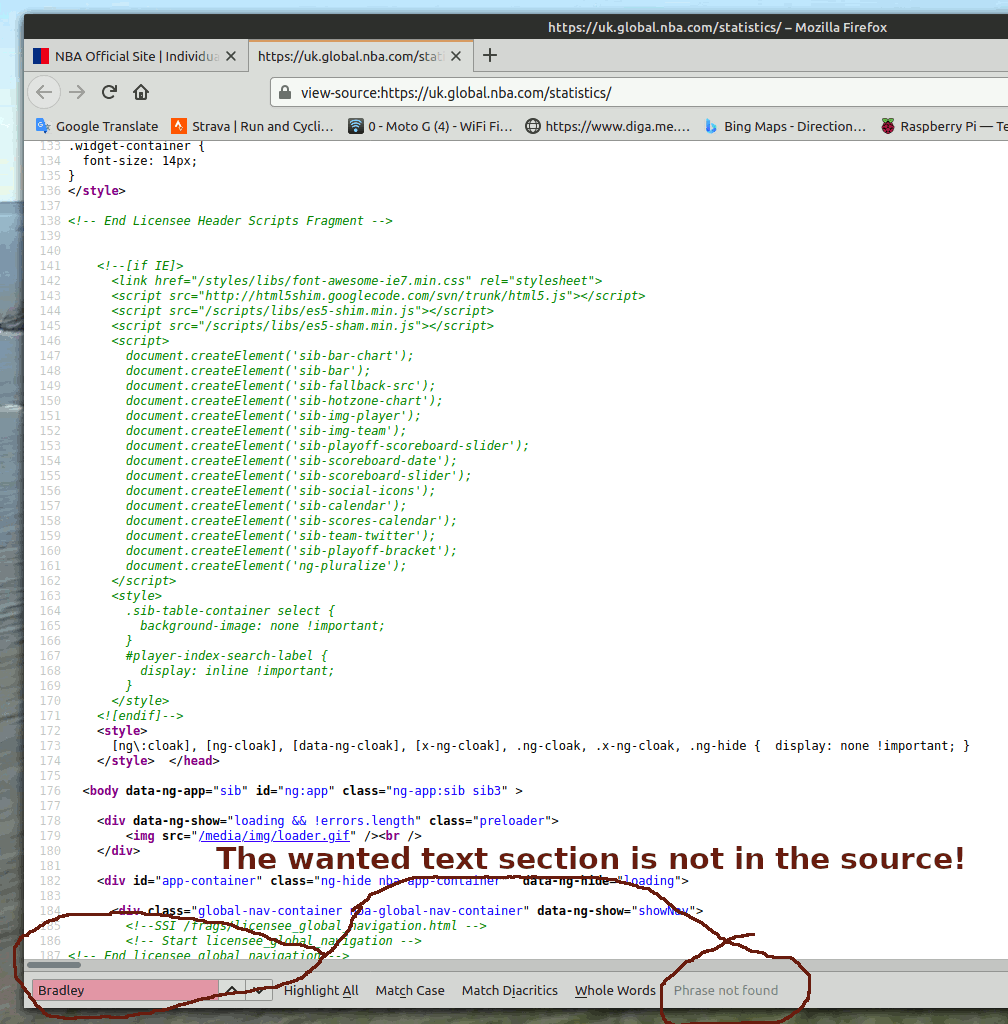
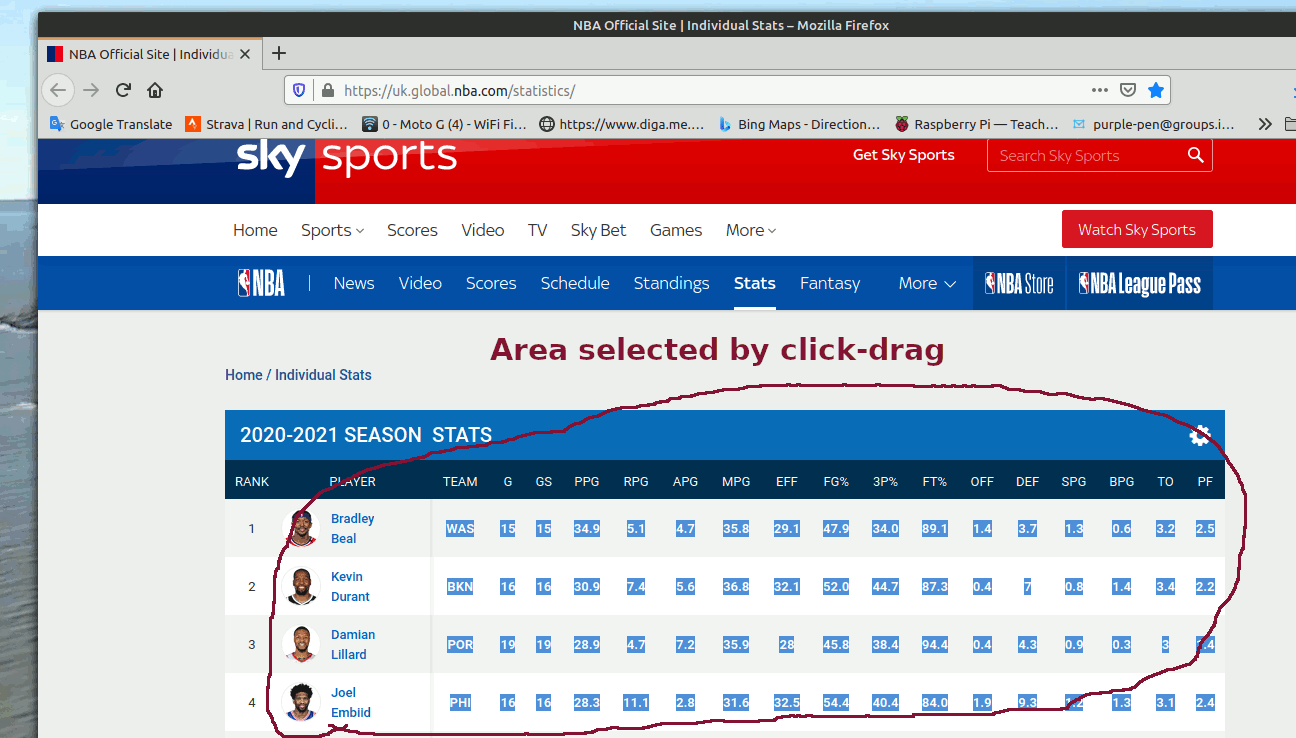
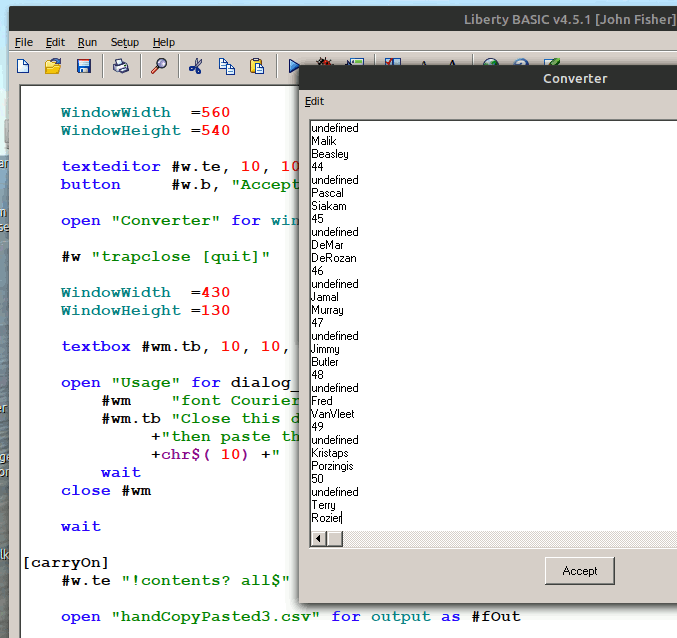
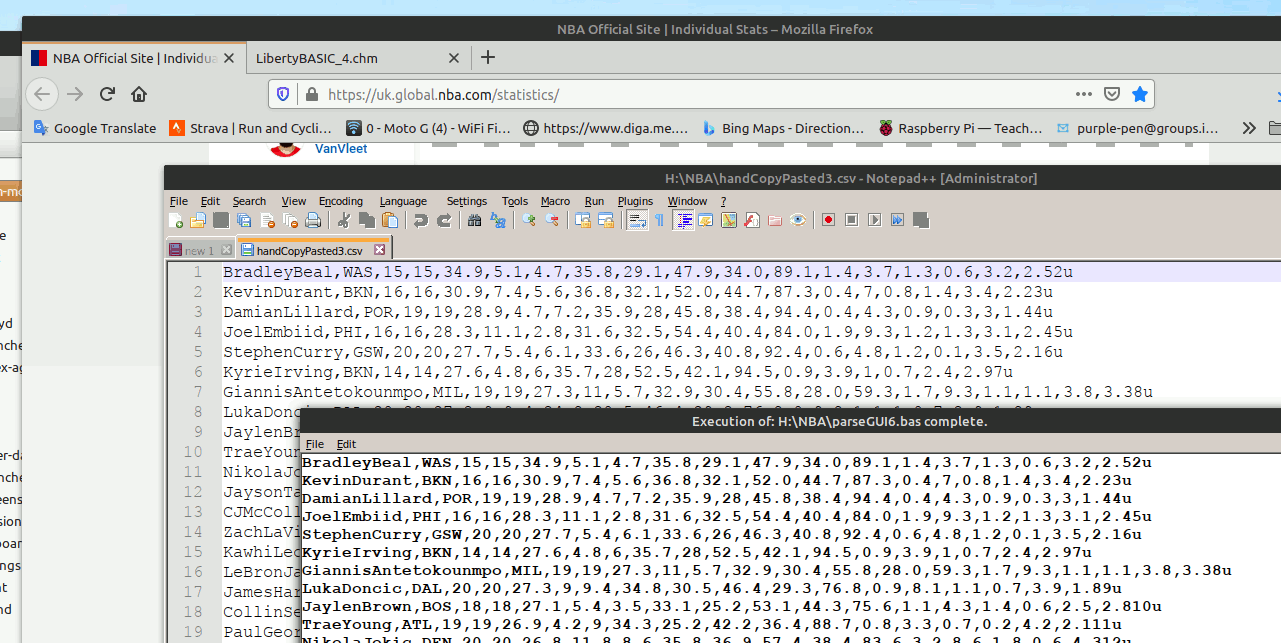
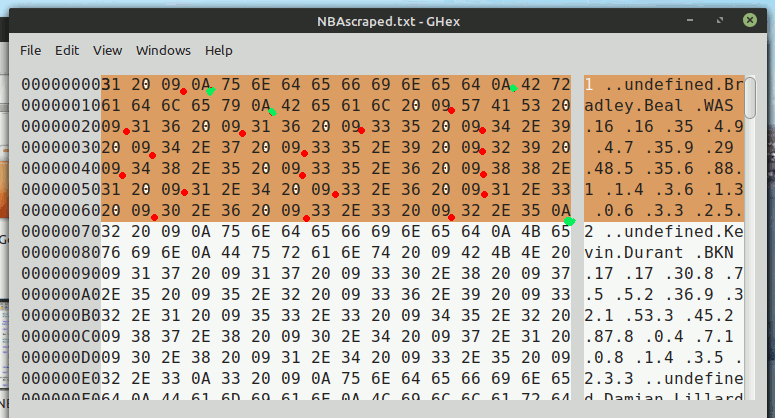
By looking at the original select/drag text I could see what the separators and delimiters were- tabs ( chr$( 9), LF ( chr$( 10), and 'undefined' as text. It is straightforward to parse it into a conventional csv file once that is understood.
HOWEVER this code works for THIS page, and does the job much faster than editing the grabbed data by hand. If the creators of the page change its format, or you want to scrape data from other pages, you'll have to do the same reverse-engineering of the relevant source code as I did! You really need to use a hex editor to see all the bytes in the captured 'scrape'.
WindowWidth =560
WindowHeight =540
texteditor #w.te, 10, 10, 550, 430
button #w.b, "Accept", [carryOn], LR, 280, 20
open "Converter" for window as #w
#w "trapclose [quit]"
WindowWidth =430
WindowHeight =130
textbox #wm.tb, 10, 10, 400, 70
open "Usage" for dialog_nf_modal as #wm
#wm "font Courier_New 12 bold"
#wm.tb "Close this dialog," +chr$( 10)_
+"then paste the copied screen section."_
+chr$( 10) +" Then click 'Accept.'."
wait
close #wm
wait
[carryOn]
#w.te "!contents? all$"
open "handCopyPasted3.csv" for output as #fOut
for g =1 to 50
delim$ ="undefined"
V =instr( all$, delim$, p)
W =instr( all$, delim$, V +1)
L =len( "undefined") +1
row$ =mid$( all$, V +L +1, W -V -L)
if len( row$) >500 then end
for i =1 to len( row$)
m$ =mid$( row$, i, 1)
if m$ =" " then
print ",";
#fOut, ",";
do
i =i +1
loop until mid$( row$, i, 1) <>" "
i =i -1
end if
if asc( m$) >32 then print m$;: #fOut, m$;
next i
print "": #fOut ""
scan
p =W
next g
close #fOut
run "C:\Program Files (x86)/Notepad++/notepad++.exe " + "handCopyPasted3.csv"
[quit]
close #w
end